2024년 10월 31일에 업데이트했습니다.
Intro
오픈소스 컨트리뷰션 아카데미에 참여한 이후로, 이제서야 첫 PR을 올리게 되었다…!!
비록 Request changes를 받고 바로 main에 올라가지는 못하게 되었지만, 과정을 남겨두면 좋을 것 같아 글로 정리하기로 했다.ㅎㅎ
현재 상황 정리...
githru-vscode-ext 엔진의 동작은 크게 아래의 4가지 함수로 구분할 수 있고, 각 함수의 커밋 약 900개 기준 실행 시간을 측정해보면 아래와 같다.
getGitLog(git log명령으로 git log 데이터를 모두 가져오는 함수) : 2.590초getCommitRaws(git log 데이터를 처리할 수 있는 형태로 파싱하는 함수) : 12.424밀리초buildStemDict(Stem을 생성하는 함수) : 6.93밀리초buildCSMDict(CSM을 생성하는 함수) : 1.266밀리초
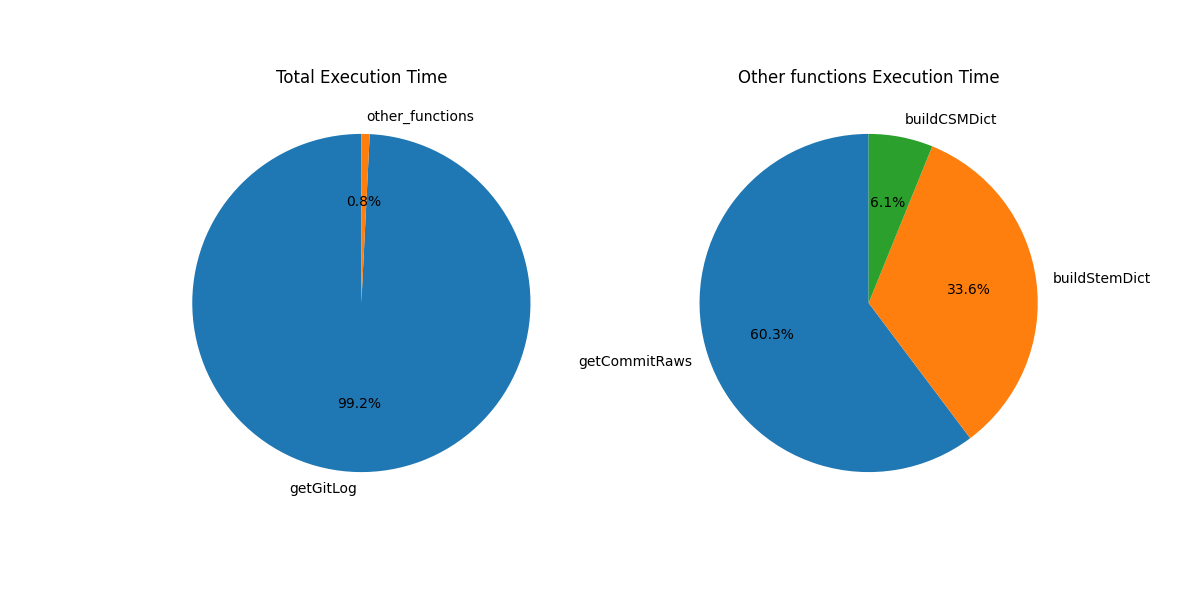
getGitLog 함수의 실행 시간이 압도적으로 길기 때문에 앞선 Challenges 기간과 Masters 기간 초반을 다른 팀과 같이 이 문제를 해결하기 위해 투자했다. 하지만 view 단에서 가상 리스트 라이브러리를 적용해서 이 문제의 크기(?)가 좀 줄어들었고 기존에 생각했던 git log를 분할해서 무한스크롤로 로드하는 방식을 적용하기 어려워졌기 때문에 그동안의 논의를 싹- 엎고 다른 방법을 사용하기로 했다.
getGitLog의 성능 개선에는 여러 개의 worker thread를 사용하는 방식을 다른 분께서 적용해주시기로 했고, 나는 코드를 처음 읽었을 때 부터 신경쓰였던 getGitLog 다음으로 긴 실행 시간의 getCommitRaws 함수의 개선을 담당하기로 했다.
원인 파악하기
getCommitRaws 함수는 getGitLog함수를 통해 가져온 git log 데이터를 파싱하는 함수이다. 기존 getGitLog 함수는 git log 형식 중 fuller 포맷과 diffstat을 함께 불러오는 --numstat 옵션을 함께 사용하고 있었기 때문에 getGitLog 함수를 통해 가져오는 git log 데이터 포맷은 아래와 같았다.
commit <hash>Author: <author>AuthorDate: <author-date>Commit: <committer>CommitDate: <committer-date><title-line><full-commit-message><diffstat>
그리고 현재의 파싱 로직은 아래의 단계로 진행된다.
-
hash, parent hash, branch 등의 각 commit별 데이터를 담을 임시 배열을 생성
const ids: string[] = [];const parentsMatrix: string[][] = [];const branchesMatrix: Refs[] = [];const tagsMatrix: Refs[] = [];const authors: GitUser[] = [];const authorDates: Date[] = [];const committers: GitUser[] = [];const commitDates: Date[] = [];const messages: string[] = [];const commitTypes: CommitMessageType[] = [];const differenceStatistics: DifferenceStatistic[] = []; -
new line 단위로 나눈 데이터를 돌면서, fuller 포맷을 파싱
splitByNewLine.forEach((str, idx) => {if (str.startsWith("commit")) {commitIdx += 1;tagsMatrix.push([]);branchesMatrix.push([]);differenceStatistics.push({totalInsertionCount: 0,totalDeletionCount: 0,fileDictionary: {},});const splitedCommitLine = str.split("(");const commitInfos = splitedCommitLine[0].replace("commit ", "").split(" ").filter((e) => e);ids.push(commitInfos[0]);commitInfos.splice(0, 1);parentsMatrix.push(commitInfos);const branchAndTagInfos = splitedCommitLine[1]?.replace(")", "").replace(" -> ", ", ").split(", ");if (branchAndTagInfos) {branchAndTagInfos.forEach((branchAndTagInfo) => {if (branchAndTagInfo.startsWith("tag:"))return tagsMatrix[commitIdx].push(branchAndTagInfo.replace("tag: ", ""));return branchesMatrix[commitIdx].push(branchAndTagInfo);});}return false;}// 일부 생략}); -
각 배열에 담긴 데이터들을 commit별로 묶어서 반환
// 각 카테고리로 담은 다음 다시 JSON으로 변환하기 위함const commitRaws: CommitRaw[] = [];// 카테고리 별로 담은 것을 JSON화 시키기for (let i = 0; i < ids.length; i += 1) {commitRaws.push({sequence: i,id: ids[i],parents: parentsMatrix[i],branches: branchesMatrix[i],tags: tagsMatrix[i],author: authors[i],authorDate: authorDates[i],committer: committers[i],committerDate: commitDates[i],message: messages[i],commitMessageType: commitTypes[i],differenceStatistic: differenceStatistics[i],});}return commitRaws;
여기서 개선 가능성이 보였던 부분이 2가지 있었다.
- 2번째 파싱 단계의 코드가 복잡하여 한 눈에 파싱 로직을 판단하기 어려움
- 파싱 조건과 실제 데이터가 맞지 않는 경우가 있음
- 기존 포맷에 있는 괄호나 공백 같은 형식을 제거하는 코드가 많음.
- 분리한 데이터를 다시 commit별로 합치는 과정은 파싱 로직을 commit 단위로 동작하도록 해서 제거할 수 있을 것 같다. ⇒ 실행 시간 단축 기대
이렇게 2가지 부분을 개선하기 위해 getCommitRaws 함수를 변경하기로 했다.
개선 과정
git 명령어들에서 데이터를 출력할 때 사용하는 포맷은 여러 가지가 있고, (옵션이 있다면) 원하는 포맷을 설정할 수 있다. 자세한 내용은 git 문서의 pretty-formats 항목에서 확인할 수 있다. git log에서는 --pretty 옵션으로 포맷을 지정할 수 있는데, 이미 내장되어 있는 포맷인 short, medium, full, fuller 같은 형식 뿐 아니라 format: 이후에 직접 placeholder들을 조합해서 포맷을 만들 수도 있다.
기존의 fuller 포맷을 파싱하던 코드가 복잡했던 이유는 내장 포맷들이 출력 결과를 보는 사람이 읽기 편하기 위한 목적으로 만들어진 포맷이기 때문이었다고 판단해서, fuller 포맷 대신 각 데이터를 특정 Separator (GIT_LOG_SEPARATOR)로 구분하여 출력하는 포맷을 만들고, String.split() 함수를 이용해서 간단히 파싱할 수 있도록 했다.
그리고 기존 파싱 로직이 commit 단위로 동작하지 않고 전체 데이터 위에서 동작했던 이유는 기존 fuller 포맷 안에는 각각의 commit을 구분할 수 있는 명확한 구분자가 없었기 때문이라고 생각해서 각 커밋별 데이터를 구분하기 위한 Separator 도(COMMIT_SEPARATOR) 추가해서 포맷을 만들었다. 이상적으로는 각 커밋들의 데이터 뒤에 Separator가 오는 것이 좋겠지만 --pretty 옵션은 --numstat으로 함께 출력하는 diffstat에는 적용되지 않아서 부득이하게 (…) 커밋별 데이터 가장 앞에 Separator를 두고 split 결과의 가장 앞 원소를 버리는 방법을 취했다.. 😕
const gitLogFormat =COMMIT_SEPARATOR +["%H", // commit hash (id)"%P", // parent hashes"%D", // ref names (branches, tags)"%an", // author name"%ae", // author email"%ad", // author date"%cn", // committer name"%ce", // committer email"%cd", // committer date"%s", // subject (commit message)].join(GIT_LOG_SEPARATOR);
결과
복잡했던 파싱 로직 코드가 split 2번만으로 비교적 간단하게 바뀌었다.
const commits = log.split(COMMIT_SEPARATOR);const [hash, parentsHashes, ref, ...rest] = commit.split(GIT_LOG_SEPARATOR);
시간 단축도 조금이나마 있었지만... ms 단위로 원래도 짧게 걸리던 작업이라 그렇게 드라마틱하지는 않다…
약 900개 커밋이 있는 레포지토리에서 측정했을 때 12.8ms → 7.09ms로 약 5.71ms의 시간 단축이 있었다.
한계 및 후속 이슈,,
코드를 짜면서는 느끼지 못했는데 PR을 작성할 때 실제 format 예시를 남기면서 느꼈던 문제가 있는데 바로 git log의 가독성이 정말 굉장히 매우 좋지 않아졌다는 문제다.

어마어마한 좌우 스크롤 보이시죠...
파싱 코드만 봤을 때에는 어떤 위치에 어떤 데이터가 있는지 명확히 알 수 있게 되었지만 막상 사용하는 git log를 봤을 때에는 도저히 어디에 뭐가 있는지 알 수 없는 포맷이 되고 말았다..
이는 Separator를 임의의 난수 string으로 사용했기 때문인데, 가독성 문제 뿐 아니라 가능성이 낮긴 해도 실제 데이터에 Separator와 동일한 string이 등장한다면 파싱에 오류가 발생할 수 있기 때문에 이상적으로는 절대 오지 못하는 string을 Separator로 설정하는 것이 좋다. 하지만 아직까지는 뾰족한 대안을 찾지 못해서 후속 이슈로 남겨두기로 했다.
또한 이런 리팩토링 경험이 많지 않아서 잘 몰랐는데,, 내가 리팩토링 시도한 부분이 engine에서 나름 중요한 부분이었기에 좀 더 많은 테스트가 필요하다는 리뷰도 있었다. 기존에 테스트코드가 있긴 했지만 간단한 테스트 케이스들 뿐이었기에 이 부분도 함께 보완해보기로 했다.
뭔가 첫 PR로 너무 핵심 기능을 건드려버린 것이 아닌가 하는 생각이 들어서 살짝 후회 아닌 후회를 하고 있긴 한데 ㅎㅎ 그래도 처음 봤을 때 부터 신경쓰였던 부분을 건드려 볼 수 있어서 다행이라고 생각한다… 후속 이슈도 힘내서 해결해보자!
(추가) 후속 이슈 마무리
githru/githru-vscode-ext PR #770
고민을 오래 했는데 생각보다 간단하게 해결이 되어 여기에 이어서 정리하기로 했다. 개선한 것들을 요약하면
- commit을 구분하는 separator를 난수에서 "\n"의 조합으로 변경했다.
- commit message 데이터를 subject와 body로 분리하고, body 앞에 space(" ") 4개의 indentation을 두었다.
이렇게 2가지이다.
가장 적용하고 싶었던 구분자는 개행문자("\n")인데, 많은 곳에서 개행문자를 이용해서 데이터를 구분하고 있기도 하고, 지금 우리의 문제였던 가독성 문제를 해결하기에도 가장 좋은 구분자라고 생각했기 때문이다. 그래서 개행문자를 여러 개 조합해서 절대 git log에 나오지 않을 문자열을 찾아보려고 했었는데, 번번히 실패했던 이유는 커밋 메시지 body와 diffstat 때문이었다.
고민했던 흔적.... : githru/githru-vscode-ext PR #708 comment
커밋 메시지 body는 여러 줄의 데이터를 입력할 수 있다. 그리고 빈 줄을 여러 개 입력할 수도 있다는 것이 문제였다.
가장 좋은 시나리오는 커밋 메시지 데이터 (subject와 body)를 로그의 가장 뒤쪽으로 옮기는 것이었는데, 아쉽게도 --numstat으로 출력하는 diffstat에는 형식을 적용할 수 없었다.
계속 고민하던 차에 멘토님께서 커밋 메시지 body 앞에 spacing을 두는 방법을 제안해주셔서 요 방법으로 깔끔한 구분자를 만들 수 있었다.!! 아래는 최종적으로 수정한 git log 포맷이다.
ff56befe52e75cf3d89411df21cc9f1eac1de1b4d0a00c9b5da77f8f57d11fe728490126e581a638HEAD -> mainyoouyeonSun Oct 6 18:18:18 2024 +0900yoouyeonSun Oct 6 18:18:18 2024 +0900커밋 메시지 title커밋 메시지 body 1커밋 메시지 body 21 0 temp.txt
이렇게 body 앞에 약속된 spacing을 두고 출력을 한 뒤에, 개행문자를 기준으로 한줄 한줄 읽어가며 spacing이 있는 경우에는 body로 파싱해주는 방식이 되었다.
for (let idx = 0; idx < messageAndDiffStats.length; idx++) {const line = messageAndDiffStats[idx];if (idx === 0)// message subjectmessageSubject = line;else if (line.startsWith(INDENTATION)) {// message body (add newline if not first line)messageBody += idx === 1 ? line.trim() : `\n${line.trim()}`;} else if (line === "")// pass empty linecontinue;else {// diffStatsconst [insertions, deletions, path] = line.split("\t");const numberedInsertions = insertions === "-" ? 0 : Number(insertions);const numberedDeletions = deletions === "-" ? 0 : Number(deletions);diffStats.totalInsertionCount += numberedInsertions;diffStats.totalDeletionCount += numberedDeletions;diffStats.fileDictionary[path] = {insertionCount: numberedInsertions,deletionCount: numberedDeletions,};}}
끝!
멘토님의 도움을 받고, 실제로 작업을 하면서 내내 느낀 것은 한 방향으로 오래 고민했을 때 잘 풀리지 않는다면 다른 방향으로 고민해보는 것이 필요하다는 것이었다. 매번 모든 데이터의 앞에다가 구분자를 두는 것만 생각했었는데, 아예 데이터의 출력 너비를 바꿔주는 방법은 전혀 생각하지 못해서 이렇게 오래 걸렸던 것 같다...
하마터면 개선은 했지만 좀 찜찜하게 마무리 될 뻔 했는데, 그래도 이렇게 활동이 끝나기 전에 나름대로 만족스러운 결과물을 낼 수 있어 정말 다행이라고 생각한다. 😄